

Top
Author
Published
16 Mar 2026Form Number
LP2390PDF size
16 pages, 609 KBSubscribed to LP2390.
Thank you for your feedback.
Abstract
The Lenovo ThinkAgile HX solution for AI is a validated, hyperconverged platform designed to simplify deployment and operation of enterprise AI inference and agentic AI workloads. Built on the ThinkAgile HX platform and validated for Nutanix Enterprise AI, the solution delivers a production-ready foundation for consistent performance, operational efficiency, and integrated lifecycle management.
The solution builds on the Lenovo and NVIDIA Hybrid AI 221 reference architecture for single-node AI inference, extending it with ThinkAgile HX validation, Nutanix Enterprise AI (NAI), Nutanix Kubernetes Platform (NKP) and enterprise-grade support. Nutanix Cloud Infrastructure (NCI) serves as the underlying operating platform for the AI factory while NAI and NKP offer a consolidated platform for deploying models, providing inference services, managing data, and handling the entire lifecycle of AI services and the Kubernetes platform. It seamlessly integrates with Nutanix Unified Storage (NUS) and NVIDIA AI Enterprise, ensuring secure and scalable AI services in virtualized and containerized environments.
By integrating Lenovo's ThinkAgile HX platform, Nutanix's AI software stack, and NVIDIA's acceleration capabilities, IT professionals can efficiently deploy, manage, scale, and govern enterprise AI projects. This approach leverages existing operational expertise, simplifies processes, and expedites the delivery of value in hybrid and multi-cloud infrastructures.
Introduction
AI adoption is rapidly accelerating across enterprises, creating a demand for scalable, GPU-optimized infrastructure that can support increasingly complex and data-intensive workloads. Organizations need datacenter solutions capable of running generative AI, machine learning, virtualized environments, and general inference workloads while maintaining operational simplicity, efficiency, and predictable performance.
Lenovo ThinkAgile HX accelerates time to outcome by delivering a fully engineered, factory-preloaded AI-ready solution that eliminates integration delays and operational guesswork, creating a faster time to production for AI workloads. With validated Best Recipes and automated lifecycle management, customers move from infrastructure to inference faster, with predictable performance and zero-error updates that keep AI pipelines continuously productive.
The Lenovo ThinkAgile HX solution for AI combines advanced compute, storage, and software components into a unified, hyperconverged architecture in a single, easy to stand up solution within the ThinkAgile HX650a V4. Lenovo and NVIDIA previously worked together to create an optimized hardware stack designed to run single node inference workloads called the Hybrid AI 221 platform, by leveraging this architecture and combining it with ThinkAgile HX validation and support, Lenovo is able to deliver a validated solution for AI inference workloads on the Nutanix AI stack. The solution can be configured here.
The Lenovo ThinkAgile HX solution for AI is powered by Intel Xeon processors, high-bandwidth NVMe storage, and NVIDIA GPUs including the RTX PRO 6000 Blackwell Server Edition or H200 NVL. It provides a foundation for AI workloads, including inference and agentic AI workloads. Integrated with NAI, NKP and NVIDIA AI Enterprise, the platform offers a secure, production-ready path to enterprise AI deployment. Nutanix Enterprise AI acts as the AI-ready software for your AI Factory, providing a unified, high-performance environment for model deployment, inference services, and end-to-end lifecycle management.
By combining Lenovo’s infrastructure, Nutanix’s AI software, and NVIDIA’s acceleration expertise, Lenovo enables IT teams to deploy, manage, and scale AI workloads confidently, making advanced generative AI and inferencing capabilities accessible to existing staff. These integrated technologies form a comprehensive, enterprise-ready solution that accelerates AI innovation while simplifying operations across hybrid and multi-cloud ecosystems.
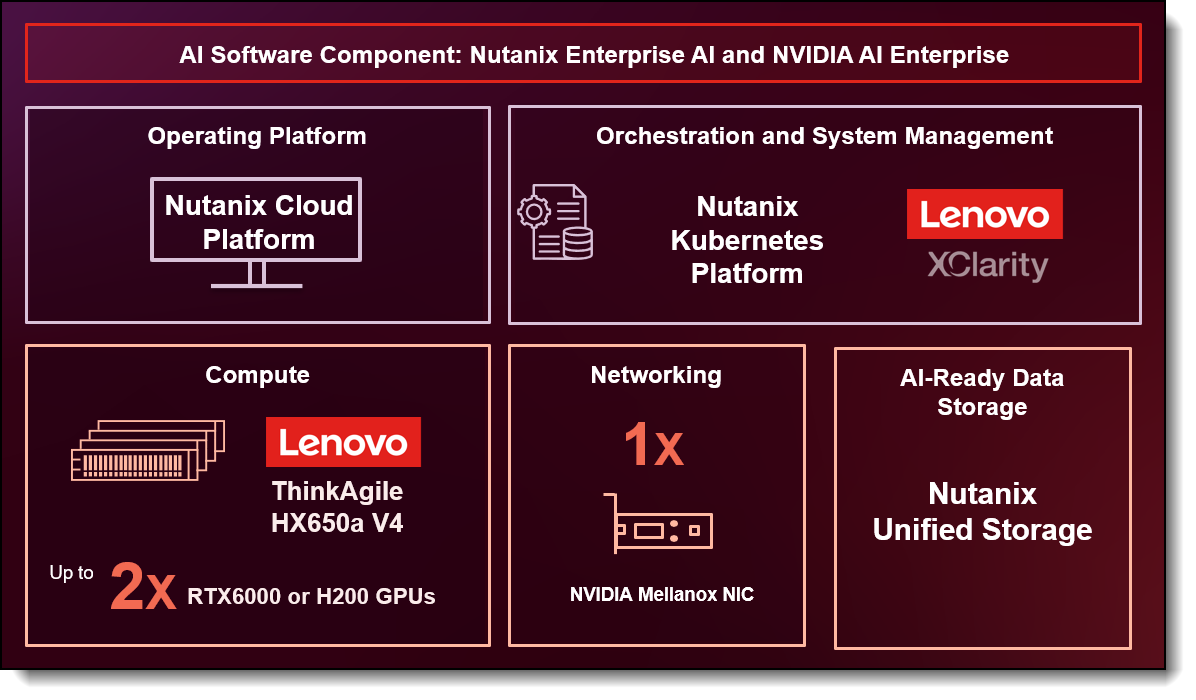
Figure 1. ThinkAgile HX solution for AI overview
Components
The main components of the solution include the AI compute node, GPUs, networking, and the software stack. The software stack consists of the operating platform Nutanix Cloud Platform, AI software components Nutanix Enterprise AI and NVIDIA AI Enterprise, orchestration and system management through Lenovo XClarity and Nutanix Kubernetes Platform, and AI-ready data storage provided by Nutanix Unified Storage
AI Compute Node
Lenovo ThinkAgile HX is a fully engineered, appliance-grade hyperconverged solution designed to simplify infrastructure operations from day-0 deployment through day-N lifecycle management. Built as a complete, pre-validated system, ThinkAgile HX arrives factory preloaded and ready to run, removing integration complexity and accelerating time to value. At the core of the solution are ThinkAgile Best Recipes which are Lenovo’s validated configuration blueprints that unify hardware, firmware, drivers, and software into a single, tested package. These Best Recipes eliminate guesswork by defining the correct update sequencing, enabling faster, zero-error updates with predictable outcomes. The result is simplified lifecycle management, consistent compliance, and predictable performance, allowing IT teams to operate with confidence while reducing operational overhead and risk.
The Lenovo ThinkAgile HX650a V4 is a 2-socket 2U hyperconverged solution for customers who want to maximize GPU compute power while deploying a fully integrated platform with Nutanix HCI software in a traditional 2U rack form factor. Built on the ThinkSystem SR650a V4 platform, the HX650a V4 supports two Intel Xeon 6700-series or 6500-series processors, along with support for two NVIDIA H200 NVL, or two RTX PRO 6000 Blackwell Server Edition GPUs in the 221 platform configuration. The HX650a V4 is designed for high-density, scale-out hyperconverged workloads, where capacity and performance scale horizontally by adding additional nodes to the Nutanix cluster.
The Lenovo ThinkAgile HX650a V4 is engineered to accelerate GPU-intensive workloads such as AI inferencing, Retrieval Augmented Generation (RAG), machine learning etc. Powered by Intel Xeon 6 processors, it delivers high GPU density and advanced internal NVMe storage for optimal performance in HCI environments. The platform supports up to 2 double-width or 8 single-width GPUs and up to 8 NVMe drives, enabling fast, low-latency data access for both compute and storage services.
A typical AI-enabled HX650a V4 node can be configured with two Intel Xeon 6530P 32-core 225W 2.3 GHz processors. With 8 memory channels per processor socket, the system delivers exceptional memory bandwidth to support GPU acceleration and virtualization overhead. A total of 512 GB of system memory is allocated to meet the requirements of the GPUs, the Nutanix OS, the hypervisor layer, and customer applications. The system can be configured with a ThinkSystem Mellanox ConnectX-6 Dx 100GbE QSFP56 2-port PCIe Ethernet adapter for or ThinkSystem Broadcom 57414 10/25GbE SFP28 2-port PCIe Ethernet adapter for networking. The 221 platform is designed to use internal NVMe storage by default for hyperconverged solutions.
In the 221 platform configuration of the ThinkAgile HX650a V4, GPUs are installed at the front of the server on Riser 7 as full-height, full-length (FHFL) GPUs.
GPU Selection
The Hybrid AI 221 platform on the ThinkAgile HX650a V4 is engineered to support the full range of NVIDIA double-width PCIe GPUs, including the NVIDIA RTX PRO 6000 Blackwell Server Edition and NVIDIA H200 NVL, enabling flexibility across diverse AI and accelerated compute workloads.
- NVIDIA RTX PRO 6000 Blackwell Server Edition
Powered by the next-generation NVIDIA Blackwell architecture, the RTX PRO 6000 Blackwell Server Edition combines advanced AI acceleration with high-end visual computing capabilities for modern data center environments. Featuring 96 GB of high-speed GDDR7 memory, it delivers exceptional performance for a wide variety of workloads, including agentic AI, physical AI, scientific simulation, rendering, 3D visualization, and video processing. This GPU offers strong versatility across both AI and graphics-intensive use cases. When deployed in platform 221, a minimum of 290 GB of system memory is recommended to ensure optimal performance.
- NVIDIA H200 NVL
The NVIDIA H200 NVL is purpose-built for demanding generative AI and high-performance computing (HPC) applications. It features an impressive 141 GB of HBM3e memory, nearly doubling the capacity of the H100, along with up to 4.8 TB/s of memory bandwidth. This combination allows the H200 NVL to efficiently process large and complex AI models, including large language models (LLMs), delivering significant performance gains. Designed with power efficiency in mind, it provides higher performance within a similar power envelope as the previous generation. NVIDIA also includes a 5-year NVIDIA AI Enterprise license at no additional cost with H200 NVL. For the 221 platform, a minimum system memory of 453 GB is recommended.
AI Software Stack
The AI Software Stack provides the platform for deploying and managing AI workloads across the infrastructure, with Nutanix Cloud Platform (NCP) forming the core operating platform. It combines Nutanix Enterprise AI (NAI) and Nutanix Kubernetes Platform (NKP) for AI model deployment and orchestration, with NVIDIA AI Enterprise delivering optimized AI frameworks and microservices. Nutanix Unified Storage (NUS) provides high-performance data services for AI workloads, while Lenovo XClarity enables system monitoring and hardware management.
Enterprise AI Software
Nutanix Enterprise AI (NAI) is a Kubernetes-based application that forms the AI platform layer of the Enterprise AI stack, giving IT teams the ability to deploy, manage, and monitor large language models (LLMs) and inference endpoints. Leveraging the capabilities of NKP, NAI provides the higher-level services required to operationalize generative AI, acting as a centralized inferencing control plane. With support for endpoint APIs from leading LLM providers, including NVIDIA NIM and Hugging Face, organizations can securely run a wide range of generative AI models on-premises or in the public cloud.
NAI includes a streamlined, UI-driven interface, role-based access controls (RBAC), and untethered deployment options for dark-site or air-gapped environments, simplifying Day 2 operations, monitoring, and adaptation of AI models with enterprise-grade resilience and compliance. This approach allows teams to quickly deploy, monitor, and manage AI models and secure endpoints, providing flexibility in model selection and making AI tools accessible across the enterprise, empowering every team to leverage AI effectively.
NAI Unified Endpoints provides consistent authentication, rate-limiting, and monitoring, with fallback and load balancing for inference endpoints, across self-run local models as well as provider models like Anthropic or OpenAI.
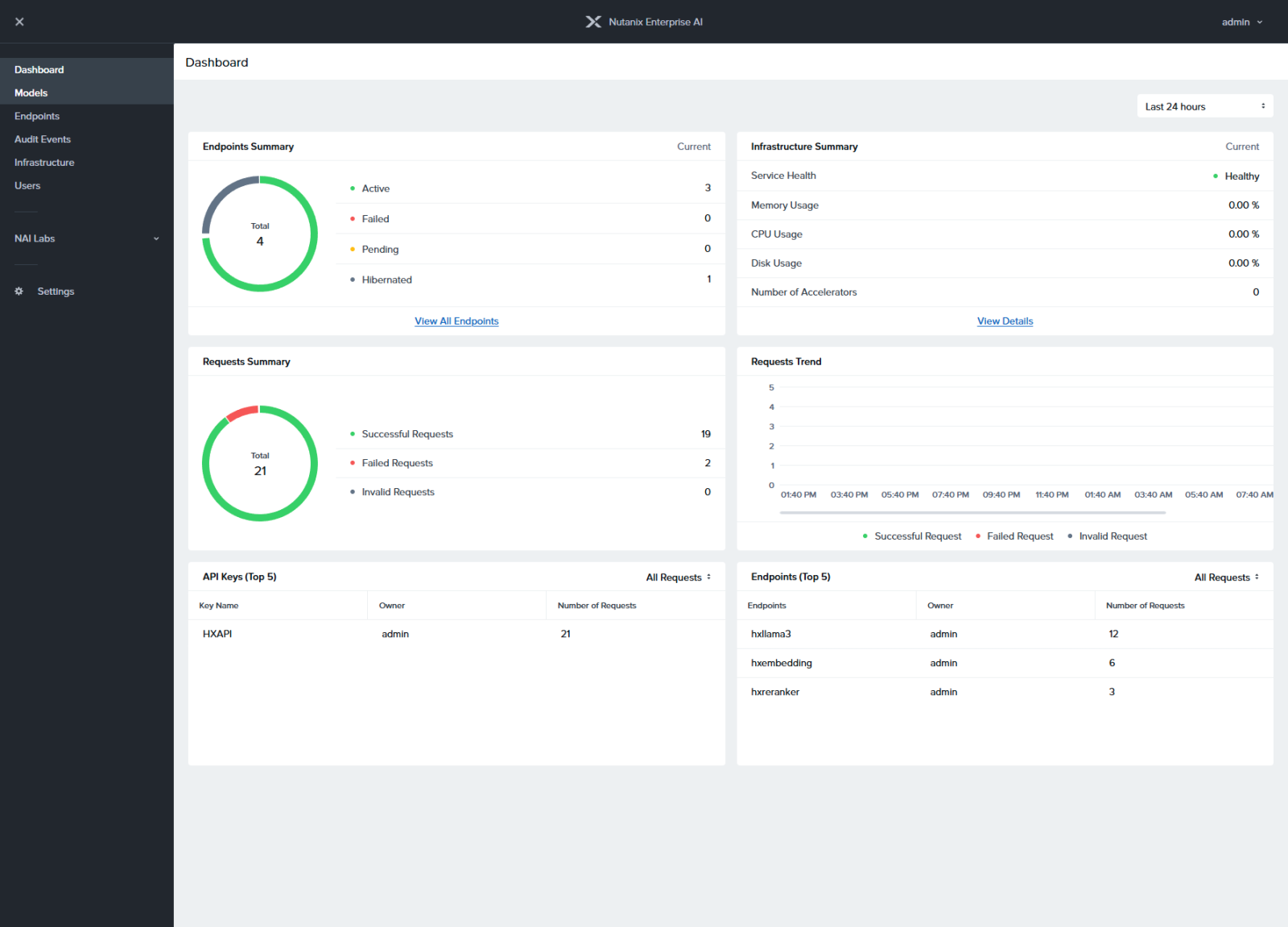
Figure 2. Nutanix Enterprise AI
Kubernetes Layer
Nutanix Kubernetes Platform (NKP) provides the enterprise-grade Kubernetes foundation for Nutanix Enterprise AI on ThinkAgile HX Series, enabling organizations to deploy and operate AI workloads with consistency, security, and scale. As the Kubernetes layer, NKP delivers a CNCF-conformant platform that simplifies cluster lifecycle management and supports production-ready deployment of AI services such as large language models (LLMs), inference APIs, and retrieval-augmented generation (RAG) pipelines.
Tight integration with software-defined compute, storage, and networking ensures efficient resource utilization, high availability, and support for GPU-accelerated workloads, making it well suited for data-intensive AI training and low-latency inference in on-premises and hybrid environments.
Together, ThinkAgile HX Series, NKP and NAI enable a secure, governed, and cloud-consistent AI platform for the enterprise. Built-in security, multi-tenancy, and policy controls allow teams to safely scale AI across business units, while Kubernetes-native portability ensures AI applications can be deployed consistently across on-prem and hybrid cloud environments. This combination provides a trusted foundation for operationalizing enterprise AI at scale.
AI Ready Data Storage
Nutanix Unified Storage (NUS) is a software-defined storage platform that brings file and object storage together into a single, integrated solution. By unifying these storage services on one platform, NUS simplifies operations while delivering high performance, dense capacity, and cost efficiency. This makes it well suited for data-heavy workloads, including AI/ML pipelines and big data analytics, where fast and scalable access to data is critical. Part of the NVIDIA STX, a specialized modular reference architecture for AI-native storage, Nutanix Unified Storage enables continuous, GPU-accelerated data transformation and vectorization directly within the storage cluster. This provides the high-performance data fabric required to bridge training and inference workloads without bottlenecks.
NUS works seamlessly with the Nutanix Cloud Platform (NCP) to deliver a consistent, high-performance storage foundation across hybrid and multi-cloud environments. By consolidating management into a single interface, NCP enables organizations to optimize performance, reduce costs, and strengthen security, while simplifying operations and allowing teams to focus on innovation. In addition, NUS is fully compatible with NKP and NAI. This integration streamlines the deployment and management of Kubernetes clusters, making it easier to run and scale AI/ML workloads. Together, NUS and Nutanix’s AI and Kubernetes tools provide a unified infrastructure solution for modern, data-intensive applications.
Nutanix Unified Storage delivers several advantages for AI and machine learning use cases:
- High Performance and Scalability - NUS is designed to meet the intensive I/O demands of AI/ML workloads, providing high-speed read/write performance using GPU-Direct protocols across thousands of GPU clients, ensuring that data availability scales just as fast as your compute, and GPUs are never starved for data.
- Flexible Deployment and Integration - The platform supports seamless integration with on-premises systems and public cloud environments, enabling smooth data movement and management across hybrid and multi-cloud architectures.
- Cost Efficiency - By consolidating multiple storage services into a single platform and providing a high-capacity tier for KV cache offloading that frees up critical GPU memory, NUS enables the systems to handle larger context windows and more users. as well as reduces operational complexity. This directly lowers overall storage costs, making it economical for managing large-scale datasets.
- End-to-End AI Enablement - From data ingestion and preparation to model training and inference, NUS is built to support the full AI/ML lifecycle with scalable and reliable storage services.
Lenovo XClarity
Lenovo XClarity Management on ThinkAgile HX Series provides comprehensive platform-level monitoring and alerting across all hardware subsystems, ensuring issues are detected and addressed before they impact workloads. Hardware events, errors, and health status are reported directly to Lenovo XClarity, giving administrators full visibility beyond the operating system layer. XClarity continues to monitor the underlying hardware independently of the OS, enabling proactive issue detection even during system outages.
Lenovo-specific alerts leverage Lenovo intellectual property and firmware capabilities to help prevent unplanned downtime. This includes live PCIe error recovery, proactive alerts for memory failures and predicted memory faults, and drive health and RAID-related alerts reported through the Lenovo XClarity Controller (XCC).
NVIDIA AI Enterprise
To deliver enterprise-grade AI on ThinkAgile HX Series, Nutanix Enterprise AI (NAI) is deeply integrated with NVIDIA AI Enterprise software and AI microservices, bringing production-ready model deployment, inference performance, and secure AI operations to your hybrid infrastructure.
- Enterprise-Ready AI Software Stack
NVIDIA AI Enterprise provides a validated, optimized software layer for AI workloads. When combined with NAI on ThinkAgile HX Series, this enables customers to deploy and manage AI models and inference endpoints with confidence, covering use cases from simple model serving to complex agentic workflows.
- Pre-Integrated AI Microservices (NVIDIA NIM & NeMo)
NAI on ThinkAgile HX Series provides direct access to NVIDIA NIM microservices and NeMo model services to simplify AI delivery. These pre-validated components accelerate GenAI deployment, reduce operational overhead, and ensure consistent performance across environments, whether at the edge, in your datacenter, or in cloud extensions. - Accelerated Performance & Scalability
NVIDIA’s software stack is engineered to take full advantage of GPU capabilities for inference and reasoning workloads. On ThinkAgile HX Series with NVIDIA GPUs, this means predictable performance, efficient resource utilization, and lower latency for AI applications compared to general-purpose deployments. - Unified & Secure AI Operations
Combined with NAI’s centralized RBAC-based user-levelaccess to models and secure endpoint abstraction, enterprises gain unified control over large language model (LLM) endpoints, secure APIs, and governance policies. This integration supports robust Day-2 operations, essential for scaling AI across business units. - Simplified Enterprise AI Adoption
By embedding NVIDIA AI Enterprise and Nutanix Enterprise AI on ThinkAgile HX Series, organizations can reduce time-to-value for AI initiatives. This combination gives IT teams a streamlined path from infrastructure provisioning to model deployment and operationalization with familiar tools and workflows.
RAG Use Case: AI-Powered Manufacturing Operations Assistant
Open-source large language models such as Meta’s Llama are trained on vast amounts of public internet data. While they understand general engineering concepts, safety standards, and industrial terminology, they do not have built-in knowledge of your organization’s specific machinery, maintenance schedules, operating procedures, or plant-level documentation.
For example, if a plant technician asks:
“What is the approved maintenance interval for CNC Machine 12 in Plant B?”
A general LLM might provide manufacturer-recommended service intervals, but it won’t know your company’s customized maintenance plan or historical service adjustments.
To bridge that gap, organizations implement Retrieval-Augmented Generation (RAG), a framework that connects large language models with internal operational knowledge.
End-User Query Workflow (RAG in Action)
- Ask Question
A technician, engineer, or plant manager submits a question to the chatbot interface.
Example: “What troubleshooting steps should I follow for recurring overheating on Press Line 3?”
- Create Embedding of Query
Instead of immediately sending the question to a text generation model, the application first converts the user’s query into an embedding using an embedding model hosted on Nutanix Enterprise AI.
- Search / Retrieval of Similar Content
The generated query embedding is compared against stored document embeddings in the vector database.
The system retrieves the most semantically similar document chunks, such as:
- Maintenance history records
- SOP troubleshooting sections
- Engineering notes from prior incidents
- Send Prompt to Inference API
The application augments the original user prompt with the retrieved contextual content. This enriched prompt is then sent to a text generation model hosted on Nutanix Enterprise AI via the inference API.
- Get Answer
The chatbot generates and returns a response grounded in the organization’s actual operational data.
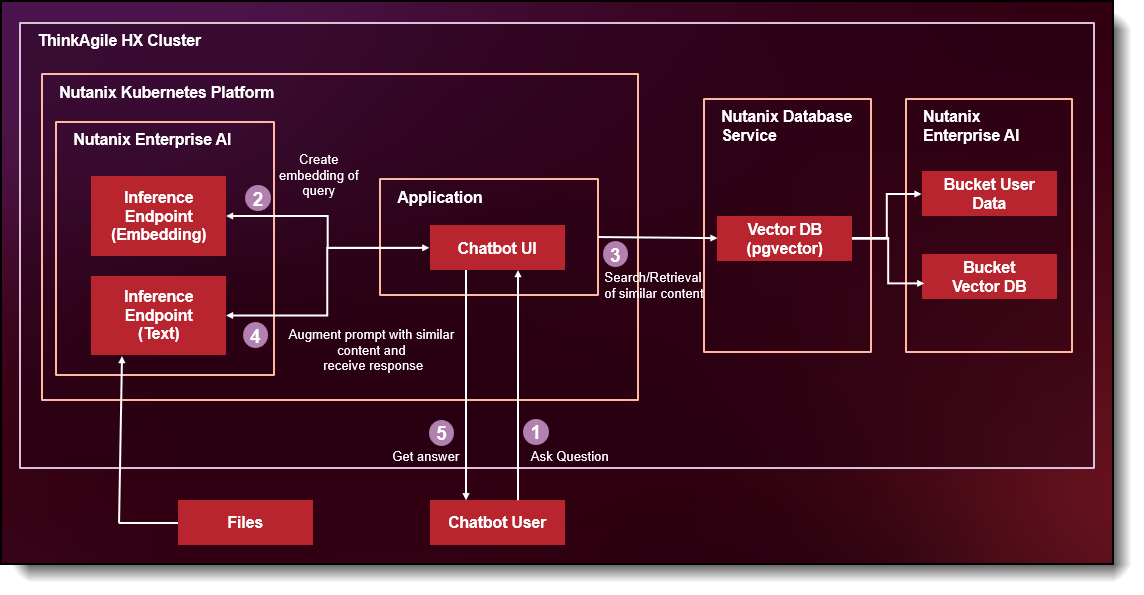
Figure 3. End-User Query Workflow
Bill of Materials - ThinkAgile HX650a V4
Configuration tips:
- NVIDIA H200 GPU can be replaced with NVIDIA RTX 6000 Server Edition GPU
- Based on the workload/use case, the Nutanix SW license quantity can be increased.
Author
Amalu Susan Santhosh is the Worldwide Technical Product Manager for Lenovo’s ThinkAgile HX and MX/SXM Series of Hyperconverged Infrastructure (HCI) solutions. Amalu is responsible for showcasing the business value and differentiation of Lenovo’s hybrid cloud solutions and contributing to the product lifecycle process.
Trademarks
Lenovo and the Lenovo logo are trademarks or registered trademarks of Lenovo in the United States, other countries, or both. A current list of Lenovo trademarks is available on the Web at https://www.lenovo.com/us/en/legal/copytrade/.
The following terms are trademarks of Lenovo in the United States, other countries, or both:
Lenovo®
ThinkAgile®
ThinkSystem®
XClarity®
The following terms are trademarks of other companies:
Intel®, the Intel logo and Xeon® are trademarks of Intel Corporation or its subsidiaries.
Other company, product, or service names may be trademarks or service marks of others.
Configure and Buy
Please select a locale
Full Change History
Course Detail
Employees Only Content
The content in this document with a is only visible to employees who are logged in. Logon using your Lenovo ITcode and password via Lenovo single-signon (SSO).
The author of the document has determined that this content is classified as Lenovo Internal and should not be normally be made available to people who are not employees or contractors. This includes partners, customers, and competitors. The reasons may vary and you should reach out to the authors of the document for clarification, if needed. Be cautious about sharing this content with others as it may contain sensitive information.
Any visitor to the Lenovo Press web site who is not logged on will not be able to see this employee-only content. This content is excluded from search engine indexes and will not appear in any search results.
For all users, including logged-in employees, this employee-only content does not appear in the PDF version of this document.
This functionality is cookie based. The web site will normally remember your login state between browser sessions, however, if you clear cookies at the end of a session or work in an Incognito/Private browser window, then you will need to log in each time.
If you have any questions about this feature of the Lenovo Press web, please email David Watts at dwatts@lenovo.com.





